

Introduction
For a comprehensive and useful explanation of Amazons Storage solution it’s really going to take more than just a single blog post. Unless that is, you want to spend the next 2 hours reading a 6000 word behemoth. As some wise person from wherever said “On a long journey, take many small steps” With that spirit in mind, lets chip away at this large subject and get to grips with AWS Storage.
First off, don’t worry! Of all the services AWS offers, it’s my opinion that storage is one of the easier ones to get your head around. It’s also one of the oldest services AWS offers. Which makes sense when you think about it as storage really forms part of the backbone of what AWS offers.
Simple Storage Service – S3
Simple Storage Service, which is almost exclusively referred to as S3. Is AWS’s solution for storing objects. Those individual objects can be up to 5TB in size. (although in reality you’re unlikely to be uploading files in the terabytes over Wi-Fi, more on this in the snowball section in part 2 of S3 explained). It is designed to store files and it does that well. What it can’t do is host operating systems, for that you’ll EBS (Elastic Block Storage).
Those files are stored in buckets. A bucket is simply a concept that Amazon devised for organising uploaded content. Essentially, they are the equivalent of folders on a traditional operating system. Where they differ from that paradigm is that the bucket names must be unique. Not just unique for your account, but globally unique for all AWS accounts! This isn’t as bad as it sounds and I was able to find unique names quicker than I initially feared.
The name of the bucket plays an important role in that it becomes part of a URL to access the buckets content over the web. The URL itself is broken down in to 3 sections:
http://s3-eu-west-2.amazonaws.com/the-bucket-name
Is there any limit as to what you can store in S3?
In short, no. Practically speaking there is no limit in how much data you can put on to S3. AWS has a regular schedule to upgrade its storage solution and constantly monitors usage. If it sees it thresholds being crosses then more storage is acquired. The end user does not have to worry about this or the management of the infrastructure. It just works!
How do you upload to S3?
AWS provides several ways to upload data to S3. The first and most obvious one is the AWS Management. A user can simply log into AWS via a browser, select the S3 service, select the bucket they wish to upload to and upload a file.
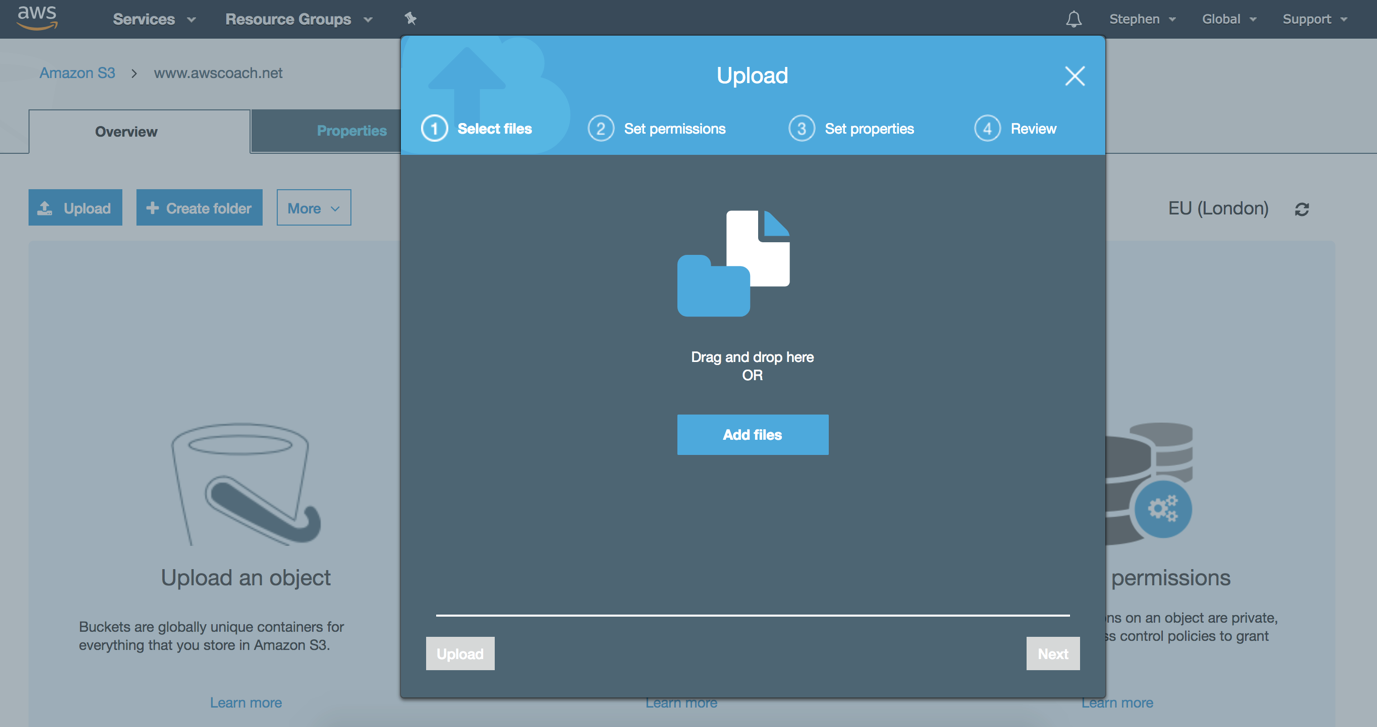
This picture shows the S3 interface (as of 2018) AWS do tend to update the look and feel periodically so what you see may not match this interface exactly. But should be fairly similar.
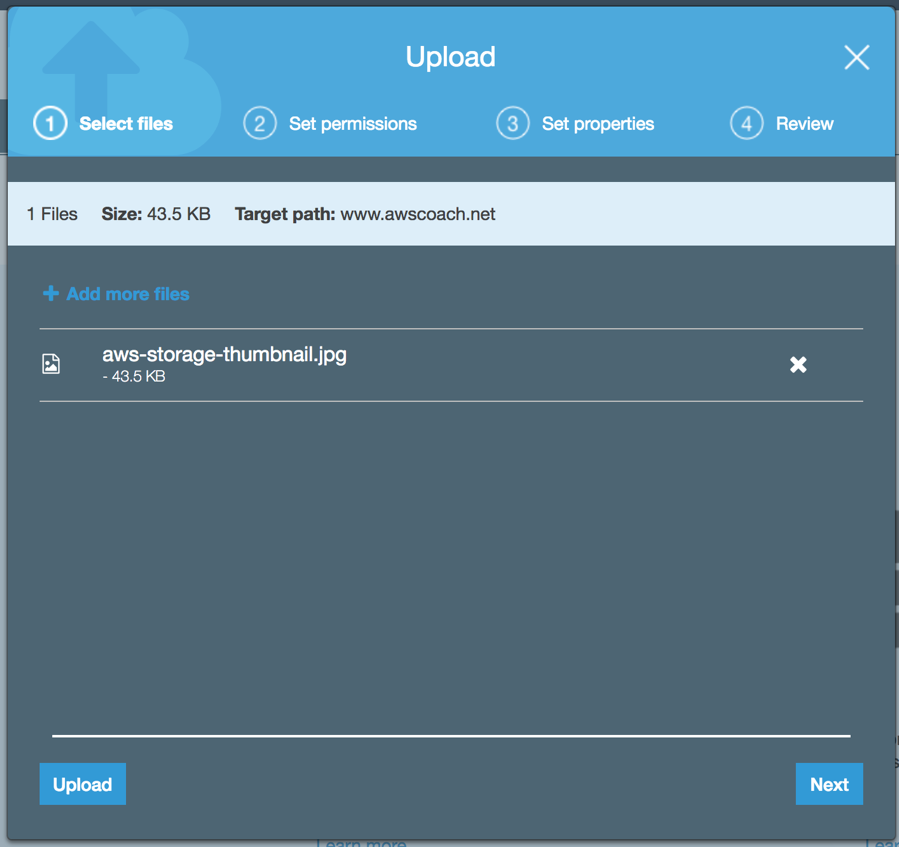
This screen grab shows the upload modal window with a file queued up for upload. You can line up as many uploads as you want and they will be pushed to your S3 bucket.
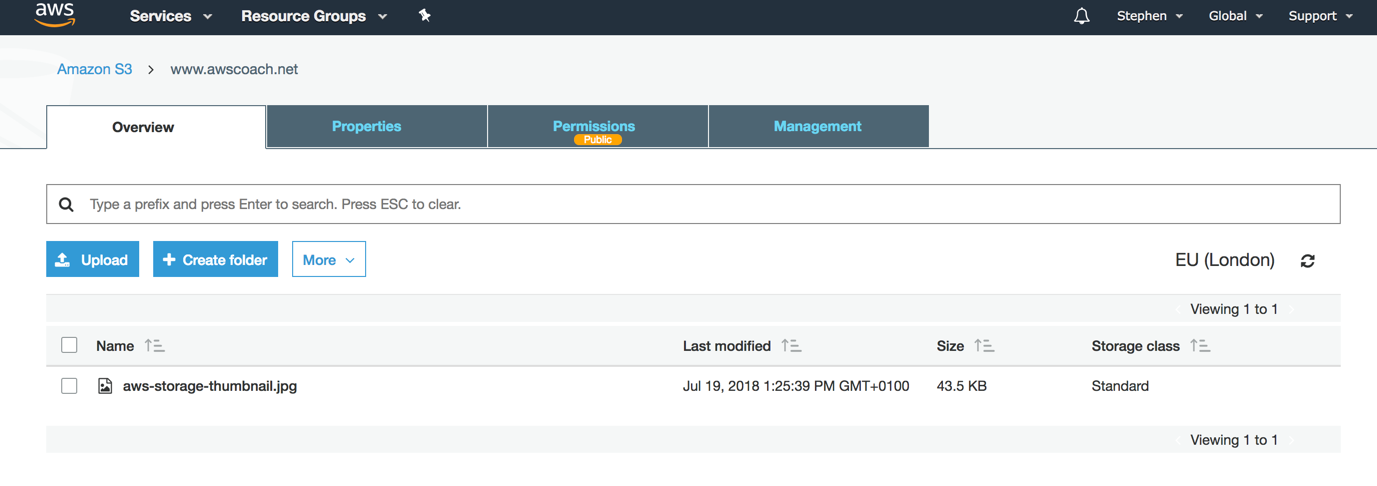
Upon successfully uploading a file it will appear in the bucket:
But what if you’ve got a slow internet connection?
Let’s say you’ve got a slow net connection or you’re uploading to a bucket on the other side of the world. In these cases, it’s not going to be practical to upload large files in a practical time scale. For instance, you’re upload video footage. To help expedite the upload process AWS provides the transfer accelerator feature. This allows users to upload files to edge locations, geographically close to the users position and then those edge locations will then push the upload to the S3 bucket using AWS’s highspeed backbone internet connection.
This results in much faster upload speeds and can drastically cut down on the time is takes to push new files.
Charges
As with most AWS services, charges tend to only occur when you start to use them and increase based on the amount of use.
Amazon provide a convenient way to estimate what different charges are applied based on the region and usage amounts here.
Essentially, you’ll be charged per gigabyte stored. You won’t be charged for uploading the content (however there is an exception to this if you opt for transfer acceleration), but you will be charged for subsequent reads.
The pricing tends to decrease based on how frequently you wish to access your data or how resilient your data is. For instance, S3 Standard storage with X3 redundancy (this is the data is duplicated to multiple separate locations) can cost almost ten times as much as say the bottom option – S3 One Zone-Infrequent Access (S3 One Zone-IA) Storage where data is still readily available however it is limited to 1 site. If that size were to fail then the data would be lost.
Resilience
One of the key differentiating factors AWS uses to price its storage products is the data’s resilience (often referred to as durability) and its availability (how reliably it can be accessed). S3 Standard data storage has a durability of 99.99999999% often referred to as the 11 nines of durability. This virtually guarantees data will not be lost, even if 2 or more sites lose the data. As for availability, AWS guarantees 99.9% availability in its SLA, but it is built with 99.99% availability.
The resilience and durability decrease depending on what sub product you place your data in. This is reflected in the cost, covered in the previous section.
When choosing what storage solution or combination or storage solutions you should consider the factors and structure your work flow to reflect them. For instance you may want to keep files after a certain amount of time (i.e. last years photo album) however you will rarely need to access them. For this, something like Glacier would be a suitable option.
Questions like this tend to pop up in the exam.
Conclusion
I initially started this article with the intention of covering at a high level all of AWS’s storage solutions. I quickly found myself diving deeper and deeper into S3 and decided that the best approach would be to cover each product individually as there’s simply too much detail that shouldn’t be missed. With that in mind, lets close part 1 of the S3 explanation. I’ll be publishing part 2 soon, where I’ll cover versioning, static web hosting, data migration to Glacier, encryption and multi region replication.
Stay tuned!